Palo Alto Firewall as Code
22 Giugno 2024










Palo Alto Firewall as Code
Sono passati circa 6 anni dall’evento Automate IT² organizzato da me e Gabriele Gerbino. Durante l’evento Xavier Homes aveva presentato un caso che mi aveva affascinato. Oggi lo potremmo chiamare: Firewall as Code.
Il mio interesse non era solo per la bellezza della soluzione, ma anche per i risvolti pratici nell’operatività e nella sicurezza.
Per diversi anni ho gestito firewall e ora, come consulente, vedo le implementazioni di tantissimi clienti. E tutte le installazioni che vedo hanno gli stessi problemi:
- centinaia di regole;
- ciascuna regola è costruita in base al sentire dell’operatore che la crea;
- nessuna cognizione, se non una piccola descrizione, sull’origine e sull’evoluzione di quella regola;
- regole, probabilmente obsolete, che rimangono configurate perché nessuno può affermare con certezza se sono necessarie o meno;
- regole che fanno riferimento a sistemi dismessi o riutilizzati e che quindi aprono rischi non ben definiti;
- regole raggruppate e semplificate semplicemente per rendere l’operatività più semplice (e quindi senza alcuna valutazione di sicurezza);
- richieste continue di aggiungere nuove regole senza ben sapere cosa un applicativo debba o non debba fare;
- impossibilità a fare una revisione per i motivi precedenti e anche perché le regole cambiano continuamente;
- enorme tempo operativo per gestire i firewall;
- nessuno è in grado di dire se le policy rispettino qualche direttiva di sicurezza di cui l’azienda dovrebbe dotarsi.
Se è vero che esistono software che hanno lo scopo di risolvere i problemi sopra, è anche vero che essi sono:
- una ulteriore pezza a processi mal disegnati;
- complicati da usare;
- talmente costosi da non essere economicamente sostenibili per la maggior parte delle aziende.
Ripartiamo dall’inizio, disegnando un processo che ci permetta di risolvere i problemi descritti sopra, da cui (e non il contrario) derivare una tecnologia che ci permetta di gestire i nostri firewall.
Nell’esempio che vediamo ho usato i firewall di Palo Alto Networks. Le motivazioni che mi hanno portato a questa scelta sono:
- li conosco abbastanza bene;
- hanno una configurazione interamente esportabile in formato testo (XML in particolare);
- posso manipolare il file di configurazione per poi applicarlo interamente in un momento successivo (commit).
L’approccio che vedremo dovrebbe essere applicabile a tutti i firewall che soddisfano queste tre proprietà.
Il processo
Il processo che voglio disegnare è molto semplice:
- i responsabili applicativi definiscono le regole di funzionamento dei propri applicativi in termini dei flussi di traffico necessari;
- i responsabili della sicurezza definiscono, ad alto livello, le policy di traffico tra le varie zone di sicurezza, secondo una valutazione del rischio;
- i security architect disegnano, implementano e presidiano le soluzioni firewall;
- l’automazione prende i requisiti di (1), applica i vincoli definiti in (2), genera la rulebase e la applica ai firewall. L’operatività dei security architect è limitata a quanto definito in (3).
Più nello specifico i responsabili applicativi devono definire i requisiti di rete tramite file e renderli disponibili assieme al codice o alla documentazione dell’applicativo (Git sarebbe un buon strumento, ma non è l’unico). Quotidianamente, o su richiesta, l’automazione aggiorna le policy.
Il modello
Come sempre la fase di modellizzazione è quella che richiede più tempo. Nell’esempio ho previsto che:
- La definizione dei servizi, in termine di protocollo/porta/applicazione, sia centralizzato e gestito dai security architect. La motivazione è che la scelta dell’applicazione da legare ad una specifica porta richiede conoscenze specifiche sulla soluzione firewall.
- La definizione delle zone di sicurezza e la relazione con le reti sia centralizzato e onere dei security architect. La motivazione è che il concetto di zona di sicurezza è legata al design di rete.
- Le impostazioni come logging e security profiles siano onere dei security architect.
- La definizione di ciascun applicativo avvenga mediante due file:
networks.ymlerules.yml. La manutenzione di entrambi i file è onere del responsabile applicativo.
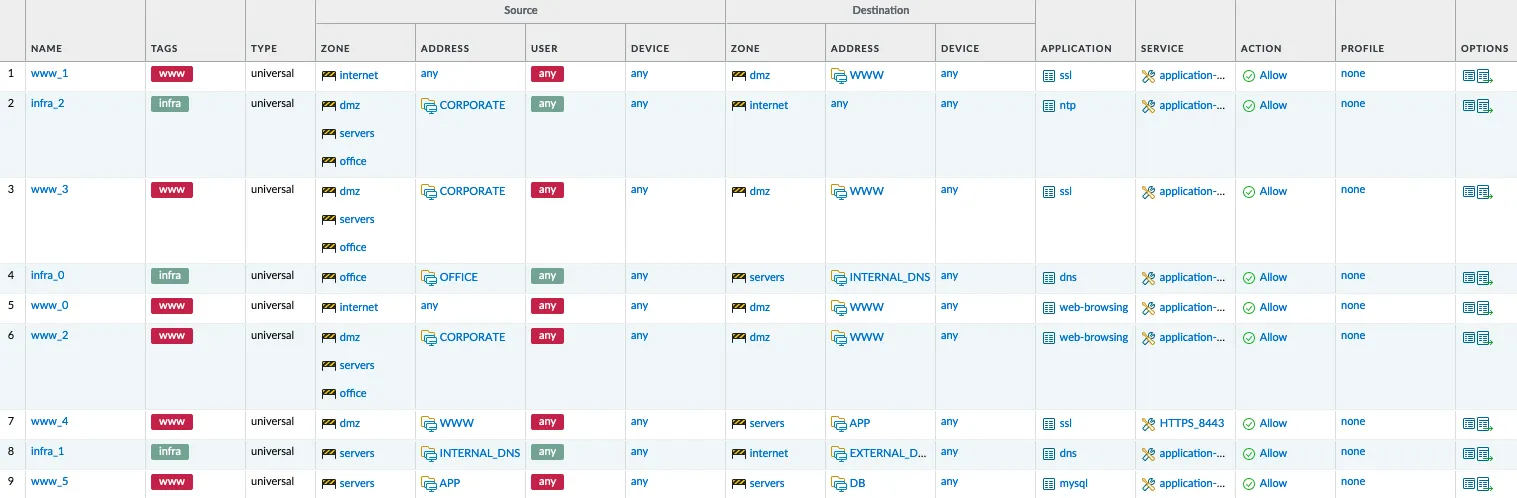
Vediamo un esempio:
# networks.yml
networks:
WWW:
- 10.20.1.7/32
APP:
- 10.20.2.15/32
DB:
- 10.20.2.23/32
Il file sopra definisce tre oggetti. WWW, APP, DB.
rules:
- destination-address: WWW
service: HTTP
description: |
Allow HTTP external traffic to exposed web server.
- destination-address: WWW
service: HTTPS
description: |
Allow HTTPS external traffic to exposed web server.
- source-address: WWW
destination-address: APP
service: HTTPS_8443
description: |
Allow traffic from exposed web server to application server.
- source-address: APP
destination-address: DB
service: MYSQL
description: |
Allow traffic from application server to database server.
Il file sopra definisce le regole di uno specifico applicativo. I servizi sono definiti nel file services.yml centralizzato:
services:
HTTP:
applications: web-browsing
HTTPS:
applications: ssl
HTTPS_8443:
protocol: tcp
port: 8443
applications: ssl
MYSQL:
applications: mysql
Le zone di sicurezza vengono associate in base alle regole definite nel file network-zone_mapping.yml:
zones:
servers:
type: internal
networks:
- 10.20.2.0/24
dmz:
type: internal
networks:
- 10.20.1.0/24
# Internet (catch all)
internet:
type: external
networks:
- 0.0.0.0/0
Ipotesi di implementazione
Riassumiamo ora i punti salienti dell’approccio:
- i security architect devono poter configurare i firewall nel dettaglio, ed è impensabile riprodurre un’interfaccia con tutte le impostazioni necessarie;
- i responsabili applicativi devono poter definire, in maniera astratta, le regole di traffico.
L’approccio più pratico, consiste quindi nel:
- leggere la configurazione aggiornata dal firewall;
- cancellare tutte le regole di traffico e gli oggetti associati;
- rigenerare, dai file descritti sopra, regole e oggetti e aggiungerli alla configurazione che era stata ripulita;
- validare la configurazione;
- applicare la configurazione.
Il vantaggio di questo approccio è evidente: non devo mai preoccuparmi di verificare se un oggetto esiste, se è corretto, se è nella posizione giusta. E questo semplifica di molto l’implementazione.
Ci sono ovviamente anche degli svantaggi, o meglio dei vincoli:
- le regole devono essere scritte in modo che l’ordine non sia importante;
- tutte le regole devono essere definite dai file descritti sopra.
Si possono ovviamente prevedere delle eccezioni, ma ciascun caso particolare complicherà l’implementazione.
Strumenti
Una volta definito il modello occorre scegliere lo strumento che tradurrà il modello in una configurazione vera e propria. Nella valutazione mi sono soffermato su:
- Aerleon (ex Google Carpica)
- pan-os-python: librerie ufficiali sviluppate da Palo Alto Networks
- pan-python: librerie sviluppate privatamente, su cui
pan-os-pythonsi basa (curioso, no?) - PAN-OS XML API
- PAN-OS CLI
Dopo alcuni tentativi fatti con la libreria ufficiale (pan-os-python), ho deciso di cambiare strada perché la libreria prevede di configurare i firewall oggetto per oggetto, mentre il mio approccio richiedeva di manipolare il file con l’intera configurazione.
Sono quindi passato ad esplorare pan-python che sembrava fare tutto quello che serviva. Tuttavia a causa della scarsa documentazione sono dovuto andare per tentativi. Ero quasi arrivato al punto di mollare e scrivermi una mia libreria che invocasse direttamente le API native.
Aerleon è una soluzione molto interessante ma non arrivava al livello di dettaglio che mi serviva. L’uso della CLI non era necessario perché i firewall Palo Alto Networks sono gestibili interamente via API native.
Implementazione
In questo momento l’automazione è implementata in un unico file Python che:
- legge la configurazione dal firewall in formato XML;
- legge l’UUID e il valore di hit count per ciascuna regola;
- cancella oggetti e regole;
- genera i nuovi oggetti e regole mantenendo l’UUID e li aggiunge al XML;
- effettua alcuni controlli di conformità;
- ordina le regole da quella più usata a quella meno;
- carica la configurazione sul firewall;
- applica la configurazione.
L’integrazione potrebbe essere aggiunta ad una pipeline CI/CD e può essere personalizzata in base alle esigenze.
Rimangono alcune cose da gestire:
- regole che devono avere un ordine specifico;
- i security profiles;
- il supporto per i gruppi di utenti;
- personalizzazioni specifiche che qualcuno sicuramente avrà.
Conclusioni
Lo sviluppo di questa automazione mi ha richiesto circa tre giorni di lavoro. Ovviamente il risultato non è production-ready ma è un buon punto di partenza.
I benefici di questo approccio sono oggettivi:
- costo operativo enormemente ridotto;
- responsabilità delle regole trasferita a chi conosce l’applicativo;
- configurazione pulita;
- possibilità di effettuare check continui sulla correttezza formale dello policy;
- performance migliorata grazie alla possibilità di ordinare le regole per utilizzo.
Se pensate che questo approccio sia avveniristico, devo svelarvi che lo speech di Xavier prendeva spunto da un’installazione reale fatta presso un cliente internazionale piuttosto grande.