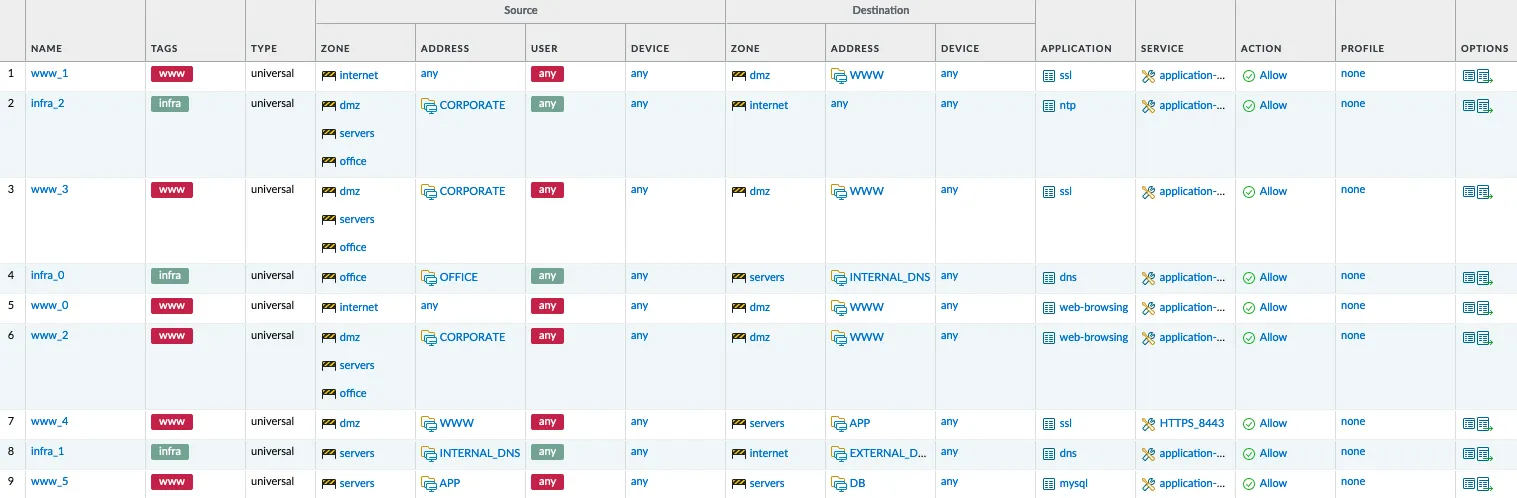
Palo Alto Firewall as Code
22 Giugno 2024









Cancellarsi da Web Archive

Web Archive è un servizio online (non-profit) che da tempo immemore registra i vari siti web archiviandoli in maniera praticamente permanente in modo che chiunque possa analizzare la storia e le modifiche di uno specifico sito Internet.
Sono un promotore dell’oblio, e sopratutto dell’essere padrone dei propri dati. In più uso spesso il motore Web Archive per il mio lavoro e conosco bene le criticità che questo tipo di servizio causa. Sebbene l’idea di fondo sia interessante, non mi piace che il servizio faccia di tutto per rendere complicato uscire da questo servizio.
Ci sarebbe infatti un comodo sistema per istruire i motori di ricerca (crawler) su come devono trattare uno specifico sito internet. Il file robots.txt permetterebbe infatti di definire, per ciascun sito Internet, cosa è consentito registrare e cosa no. Ma, appunto, Web Archive lo ignora.
Vediamo quindi, ad oggi, come essere parzialmente ignorati da Web Archive. Dico parzialmente ignorati perché pare che il motore continui a visitare le pagine che non sono però ricercabili.
Per prima cosa il file robots.txt deve essere inutilmente configurato per dichiarare a Web Archive di ignorare il sito web:
User-agent: archive.org_bot
Disallow: /
A questo punto andiamo ad aggiungere il file verify.txt sulla root del sito web con il seguente contenuto:
please remove from archive.org
Infine inviate un’email a info@archive.org richiedendo la cancellazione del dominio e dei dati associati dall’archivio di Web Archive:
I am NAME SURNAME owner of EXAMPLE.COM. I'm officially requesting the immediate removal of my site from all archive.org products. The "User-agent: archive.org_bot Disallow: /" code present in our robots.txt file is not being honored. It can be seen at:
https://www.example.com/robots.txt
I am requesting removal of EXAMPLE.COM from all stored dates, including today, and all days going forward. I have been the sole owner of this domain since inception. I have sent this message from my private address, but you can reply to any address hosted at the domain which should be removed. I have also placed a confirmation message at the following link:
https://www.example.com/verify.txt
Thank you for your prompt attention.
DMCA Notice:
I am the site owner and sole copyright holder for each of the domains cited above. This letter is official notification under Section 512(c) of the Digital Millennium Copyright Act ("DMCA"), and I seek the removal of the aforementioned infringing material from your servers. Archive.org does not have any right or permission to reproduce, sell or display my websites in any way, shape or form. I am providing this notice in good faith and with the reasonable belief that rights I own are being infringed. Under penalty of perjury I certify that the information contained in the notification is both true and accurate, and I am the copyright owner and therefore have the authority to act on behalf of the owner of the copyright(s) involved. Thank you for your prompt assistance with this matter.
NAME SURNAME
EXAMPLE.COM
Dovreste ricevere a breve una conferma dell’avvenuta cancellazione.
Sia chiaro, il mondo non sarà migliore e nemmeno più sicuro dopo questa azione, ma rimane un’azione da valutare. Sempre più servizi oggi fanno crawling di qualsiasi dato pubblico, per fini anche commerciali. Mi vengono in mente le varie AI generative, i motori di ricerca, servizi di sorveglianza (Clearview AI), il cyber crime…